
A Paradigm Shift in Data Analytics with the Rise of Large Language Models
In the dynamic landscape of data analytics, a transformative force is reshaping the way we approach data-driven decision-making. The…
In the dynamic landscape of data analytics, a transformative force is reshaping the way we approach data-driven decision-making. The emergence of Large Language Models (LLMs) has transcended the confines of Natural Language Processing (NLP), setting in motion a transformative wave across various industries, from healthcare and finance to marketing and entertainment. Their growing repertoire of capabilities have the potential to break down traditional barriers, making data accessible to a broader spectrum of users.
LLMs play a pivotal role in the democratization of data by enabling individuals with varying levels of technical expertise to interact with and derive insights from complex datasets. The intuitive nature of natural language interfaces empowers non-technical stakeholders to pose queries and extract meaningful and actionable insights without the need for specialized coding or data analysis skills. This shift in accessibility fosters a more inclusive approach to data-driven decision-making, where business leaders, product managers, marketers, and frontline employees can actively participate in the data analysis process.
In this blog, we will venture into a future where data analytics and LLMs converge, paving the way for a new era of data-informed decision-making and innovation.
Traditional Approach to Data Analytics
In the traditional paradigm of data analytics, there are several inherent downsides that organizations grapple with as they navigate the complexities of data-driven decision-making.
Siloed Skillsets and Expertise
One significant draw back lies in the siloed nature of the skillsets and expertise required to create data analytics solutions. Traditionally, data engineers possess specialized skills in database management, data warehousing, and ETL (Extract, Transform, Load) or ELT processes. They design and maintain the infrastructure to store and process data. On the other hand, data analysts specialize in data interpretation, statistical analysis and visualization. They employ SQL, Python or R to extract insights from structured data. This division often results in a communication gap, delays and misunderstandings, hindering the seamless flow of insights from the raw data to actionable insights as well as impeding the agility required in today’s fast-paced business environment.
Time-Consuming Sequential Workflow
The traditional process involves a sequence of steps that are particularly cumbersome with large datasets, from data collection and cleaning by data engineers to analysis and visualization by data analysts, presenting a substantial time constraint. In an era where real-time decision-making in imperative, delay in the delivery of crucial insights can be a significant disadvantage.
Limited Accessibility to Data for Non-Technical Stakeholders
A notable challenge in the traditional approach is the limited accessibility of data for non-technical stakeholders. The dependency on analysts as intermediaries creates a bottleneck, as non-technical stakeholders may struggle to directly analyze the data. This limitation inhibits a more inclusive and collaborative approach to decision-making, as insights are filtered through a technical lens before reaching key stakeholders.
Resource-Intensive Manual Querying and Analysis
Manual querying and analysis, though effective, come at a cost. Analysts invest substantial time and effort in crafting intricate queries and conducting in-depth analyses. While this meticulous approach ensures accuracy, it can be resource-intensive, slowing down the pace at which insights are generated. As datasets grow in complexity and volume, this manual aspect of analysis becomes a bottleneck, hindering organizations from swiftly adapting to dynamic business scenarios.
Summary
In conclusion, the downsides of the traditional approach to data analytics underscore the need for a more integrated and agile methodology. As we explore alternative paradigms, such as leveraging Large Language Models (LLMs), it becomes increasingly apparent that overcoming these traditional limitations is not merely about adopting new tools but fundamentally rethinking how organizations approach the entire data analytics process.
Approach with Large Language Models (LLMs)
Data Engineering
Evaluation of GPT-3 for Data Wrangling
The paper “Can language models automate data wrangling?” (2023) compares the effect of applying GPT-3 (prompts, few-shot) to a wide range of data wrangling problems with the results of specialized data wrangling systems and other tools. The comparison results show that GPT-3 is promising though its performance varies across domains and tasks, with strengths in simple string transformations and struggles with complex tasks requiring arithmetic operations. Although LLMs is versatile in the data engineering domain, challenges remain in understanding more complex tasks and handling anomalies.
Paper is available at: https://link.springer.com/content/pdf/10.1007/s10994-022-06259-9.pdf?pdf=button
Code is available at: https://github.com/gonzalojaimovitch/lm-dw-v2
SQLMorpher
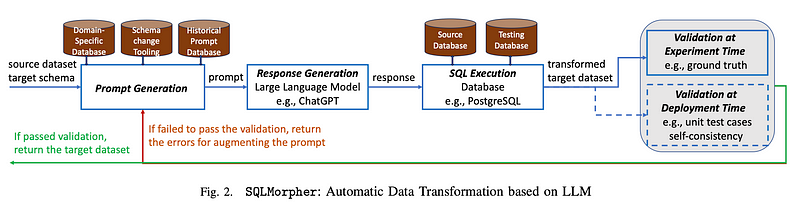
SQLMorpher consists of four components:
1. Prompt Generator:
I. A prompt template that incorporates minimal information from users, including source and target table schemas and examples of tuples. Additional optional information includes domain-specific details, schema change hints, and demonstrations for few-shot learning
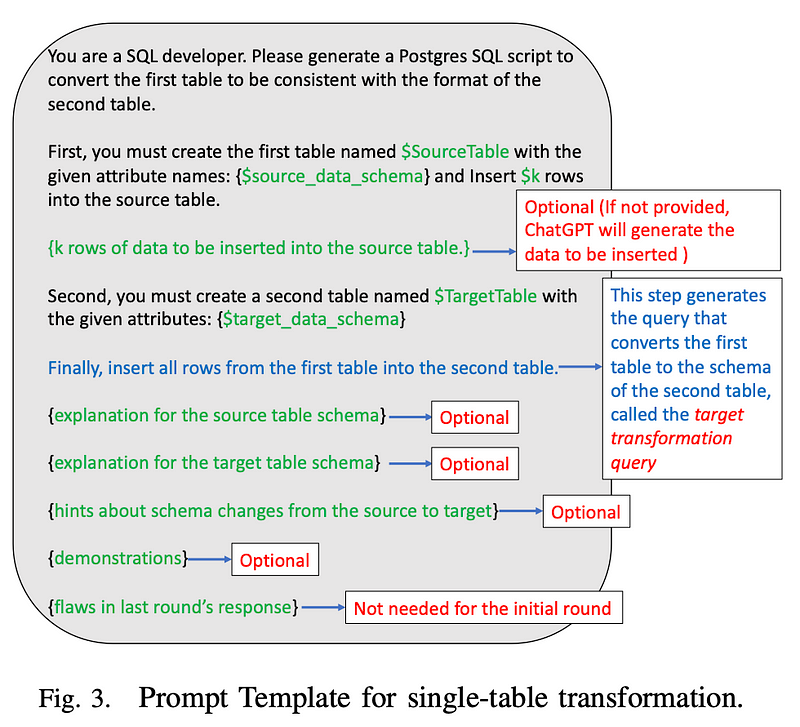
II. Callback System: Retrieve various types of information to enhance the prompt and allow the users to register callback functions for each type of information.
2. Large Language Models (e.g., GPT-4)
3. SQL Execution Engine: Executes generated SQL queries in a sandbox environment, isolating errors and ensuring the integrity of the source dataset
4. Iterative Prompt Optimization Component: Iteratively refine prompts based on identified errors until the generated query passes validation
SQLMorpher demonstrates that LLMs are promising to automatically resolving complicated data transformation cases if domain-specific knowledge is available and easily retrievable. It outperforms other state-of-the-art automatic data transformation tools that do not rely on LLMs, with SQLMorpher achieving an impressive 81% accuracy compared to Auto-Pipeline’s 69% on a commercial benchmark. The flexibility of SQLMorpher in handling diverse schema change types, guided by high-level hints like column mapping relationships, positions it as a promising solution for complex and varied data transformation challenges.
Moreover, SQLMorpher’s iterative optimization framework sets it apart by enhancing prompts based on errors reported by GPT or SQL execution errors in each iteration. This approach contributes to the tool’s adaptability, addressing 9.5% of cases for Prompt-3 and 5% for Prompt-1 and 2.
Paper is available at: https://arxiv.org/pdf/2309.01957.pdf
Code is available at: https://github.com/asu-cactus/ChatGPTwithSQLscript
Data Visualization
LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models
LIDA is structured around four core modules: SUMMARIZER, GOAL EXPLORER, VISGENERATOR, and INFOGRAPHER
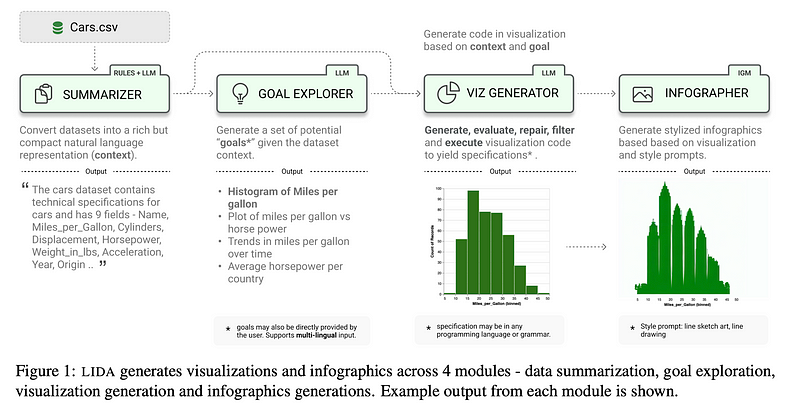
The SUMMARIZER module aims to provide context for visualization tasks by generating concise and informative summaries for datasets. The process involves two stages. First, a base summary is created, extracting dataset properties, general statistics, and samples for each column. The second stage allows enrichment of the summary through an LLM or user input, adding semantic descriptions and field predictions.
The GOAL EXPLORER generates data exploration goals based on the summary generated by SUMMARIZER. This module expresses goal generation as a multitask problem where the LLM produces a question, a visualization addressing the question, and a rationale for a more semantically meaningful goal.
The VISGENERATOR module generates visualization specifications. It consists of three submodules: code scaffold constructor, code generator, and code executor. Code scaffolds, supporting various languages and grammars, are completed based on the summary and goal. The generator uses an LLM to produce visualization code specifications, and the executor executes and filters the results.
Given that LIDA represents visualizations as code, the VISGENERATOR also implements submodules to perform operations on this representation. Operations on generated visualizations include natural language-based refinement, explanations, accessibility descriptions, self-evaluation and repair, and recommendations for additional visualizations.
The INFOGRAPHER module generates stylized graphics based on the output from VISGENERATOR. It utilizes a library of visual styles and applies them using text-conditioned image-to-image generation capabilities, allowing for the creation of informative and visually appealing infographics.
LIDA’s methodology integrates natural language processing and visualization generation to enable a seamless and interactive data analysis experience, incorporating user input and LLM capabilities throughout the process. LIDA is able to generate visualizations with a low error rate (VER = 3.5%)
Paper is available at: https://aclanthology.org/2023.acl-demo.11.pdf
Code is available at: https://github.com/microsoft/lida
Chat2VIS
The Chat2VIS system takes NL queries through a Streamlit NLI app. Users enter free-form text describing their data visualization intent and can choose from different LLMs for script generation. The system utilizes an OpenAI Access Key for model access, and the generated Python scripts are rendered within the Streamlit NLI.
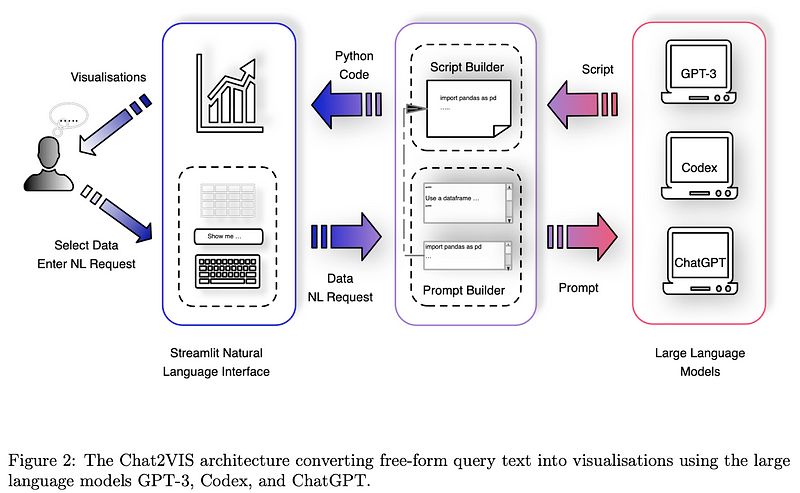
- Prompt Engineering: The key to obtaining desired LLM output is using a “show-and-tell” technique within the prompt. The system generates a prompt consisting of a Description Prompt (built from a Python docstring) and a Code Prompt (Python code statements). The Description Prompt includes information about the dataset structure, column types, and values. The Code Prompt provides guidance for script generation.
- Script Refinement and Rendering: The returned Python script from the LLMs is refined by inserting the Code Prompt at the start, and unnecessary instructions are eliminated. The refined script is then rendered on the interface. Users can further enhance visualizations by refining their NL query, requesting alternative chart types, colors, labels, etc.
The evaluation of Chat2Vis involved testing its performance across different datasets and NL queries, showcasing its effectiveness in generating visualizations from natural language input. Results indicated that Chat2Vis consistently produced informative visualizations, often surpassing or matching existing benchmarks.
Paper is available at: https://arxiv.org/pdf/2302.02094.pdf
Code is available at: https://github.com/frog-land/Chat2VIS_Streamlit
GPT-4 for Data Analysis
The paper “Is GPT-4 a Good Data Analyst” provided another framework for streamlining the tasks of data analysts.
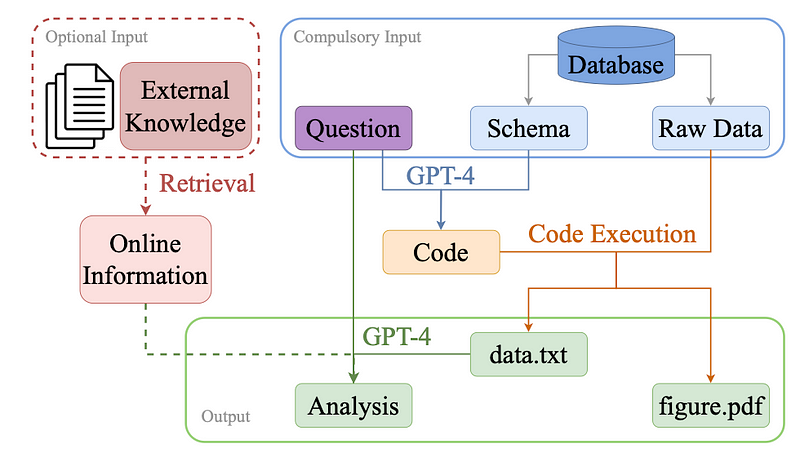
The process consists of three main steps: (1) Code Generation, where GPT-4 generates Python code based on a given question and database schema, (2) Code Execution, where the generated code is executed offline using raw data from the database to produce charts and extracted data, and (3) Analysis Generation, where GPT-4 generates insights and analysis based on the extracted data and the original question. To enhance practicality, an option is introduced to incorporate external knowledge by querying real-time information from online sources using an external knowledge retrieval model. This additional step involves GPT-4 considering both the data and external information to generate the final analysis.
This GPT-4-based framework for data analytics shows strong performance in generating accurate chart types and aesthetically pleasing figures. While information correctness in figures has room for improvement, the analysis generated aligns well with queries. Comparisons with human data analysts indicate comparable performance, with GPT-4 demonstrating cost-effectiveness, requiring substantially less time.
Paper is available at: https://arxiv.org/pdf/2305.15038.pdf
Code is available at: https://github.com/DAMO-NLP-SG/GPT4-as-DataAnalyst
Benefits of Approach with LLMs
- Democratization of Data through Natural Language Interaction: By enabling users to interact with data through natural language queries, the LLM approaches, such as Chat2VIS and LIDA, empower non-technical users to directly interact with and derive insights from data. This accessibility promotes inclusivity and collaboration, and expands participation in decision-making processes.
- Automation and Efficiency: The LLM approaches automate manual tasks, such as manually writing SQL queries and generating data visualizations, leading to significant time and effort savings.
- Enhanced Context Understanding: The traditional approach to data analytics mostly focuses on structured data; on the other hand, LLM approaches excel in understanding context, allowing for nuanced queries and providing more relevant insights when dealing with unstructured or complex datasets.
- Continuous Learning: LLMs can continuously learn from user interactions, improving their understanding of data patterns over time. This adaptive learning contributes to more personalized insights.
Potential Limitations and Considerations
- Handling Large and Complex Datasets: LLMs may encounter difficulties when dealing with extremely large or highly complex datasets. Ensuring scalability and efficient processing of diverse data structures is essential to overcome these challenges
- Ethical Concerns in Data Usage: Organizations using LLMs must address ethical considerations, including privacy preservation, mitigation of biases in training data, and ensuring transparency in decision-making processes.
- Low Resource Grammars: LIDA’s problem formulation relies on LLMs having knowledge of visualization grammars present in their training dataset. For visualization grammars not well-represented, or for complex tasks beyond the expressive capabilities of specific grammars, LIDA’s performance may be limited. Further research is needed to study the effects of strategies like task disambiguation, impact of task complexity, and the choice of programming language/grammar on performance
- Deployment and Latency: Large language models, like GPT-3.5, are computationally expensive and demand significant resources for low-latency deployment. Deployment complexity is increased by the current setup’s code execution step, requiring a sandbox environment. Research opportunities include training smaller, capable LLMs, and designing vulnerability mitigation approaches to limit program scope or generate only input parameters.
- Explaining System Behavior: The approach simplifies the design of visualization authoring systems but inherits interpretability challenges associated with large language models. Further research is needed to explain system behavior when and why explanations are needed and provide actionable feedback to users.
- Displacement of Labor: The deployment of LLMs in data analytics may lead to a displacement of labor, requiring ethical considerations and responsible management of workforce transitions.
In summary, the shift toward LLMs in data analytics offers an intuitive, efficient, and collaborative approach. While benefiting from natural language interaction, automation, and continuous learning, organizations must carefully navigate potential limitations and ethical considerations to harness the full potential of LLMs in data-driven decision-making.
Reference
Jaimovitch-López, G., Ferri, C., Hernández-Orallo, J. et al. Can language models automate data wrangling?. Mach Learn 112, 2053–2082 (2023). https://doi.org/10.1007/s10994-022-06259-9
Sharma, A., Li, X., Guan, H., Sun, G., Zhang, L., Wang, L., Wu, K., Cao, L., Zhu, E., Sim, A., Wu, T., & Zou, J. (2023, September 6). Automatic data transformation using large language model: An experimental study on Building Energy Data. arXiv.org. https://arxiv.org/abs/2309.01957
Victor Dibia. 2023. LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 113–126, Toronto, Canada. Association for Computational Linguistics.
Maddigan, P., & Susnjak, T. (2023, February 12). Chat2VIS: Generating data visualisations via natural language using CHATGPT, codex and GPT-3 large language models. arXiv.org. https://arxiv.org/abs/2302.02094
Cheng, L., Li, X., & Bing, L. (2023, May 24). Is GPT-4 a good data analyst?. arXiv.org. https://arxiv.org/abs/2305.15038